

A Third Phase of Internet Search
The history of internet searching can be divided into three phases.

User searches for "Thailand", and the page containing "Thailand" the most times is chosen by search engine.
Phase 1 : Naive trust
The primitive search engines of the early internet trusted the metadata of documents completely. So companies hoping to show up in more searches began to fill their metadata tags with popular search phrases, often repeating popular words hundreds of times.
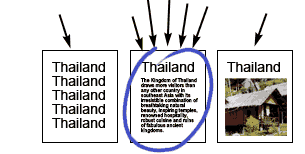
User searches for "Thailand", and the page with the most incoming links is chosen by search engine.
Phase 2 : PageRank and inferred quality
The second phase began with Google, who overcame this problem by not trusting the pages themselves, but by inferring "referrals" from external links. Links to a page by other pages were taken to be positive endorsements of that page. More incoming links meant a better search position. (Google called this measure of a page's importance PageRank.) The implicit logic was that these incoming links could be trusted because they presumably were made by someone other than the author of the page. This made it harder to falsely inflate your search rank, but it wasn't long before tricksters were finding ways to sneak "false links" onto pages to achieve the same inflated search rank for chosen pages. (Common techniques are googlebombing and spamdexing.)
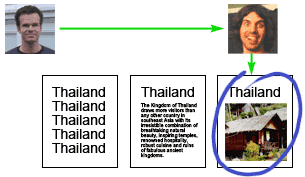
User searches for "Thailand", and the page containing photos of a friend's Thailand vacation is chosen search engine.
(For best results, this would require complete integration with a search engine's database. That's not possible at the moment, so the current Outfoxed can only re-order the search results that are returned by a search.)
Phase 3 : Social networks to determine subjective quality
Outfoxed is the tip of the next phase of searching. Instead of blindly assuming that every link on the web is an endorsment placed there in good faith, it allows for explicit assesments of quality to be given. These assesments are not all treated equally, but preference is given to those that are closer to the searcher within a [sort of*] social network. People closer to the searcher are more likely to share the searchers values. This system alows for high quality sites to shine, and poor quality sites to be weeded out. (By using the unique properties of small-world networks. See also Keeping your network clean.)
 Every search query is a question: "What pages are most related to X?" Current search engines assume there is a single correct answer to each query. But consider a query like "Britney Spears." (The most popular Google query for 2004.) If you're a fan, you probably want to see her official site and maybe lyric pages. If you're a musician, you probably want to see reviews and music tabs. Of course, current search engines can't do this because they only consider "objective" measures like the number of links to a page. (See The good, the bad, and the subjective) What is needed is subjective, trusted ratings of the pages.
Every search query is a question: "What pages are most related to X?" Current search engines assume there is a single correct answer to each query. But consider a query like "Britney Spears." (The most popular Google query for 2004.) If you're a fan, you probably want to see her official site and maybe lyric pages. If you're a musician, you probably want to see reviews and music tabs. Of course, current search engines can't do this because they only consider "objective" measures like the number of links to a page. (See The good, the bad, and the subjective) What is needed is subjective, trusted ratings of the pages.
[A new search engine, Zniff, takes a step in the right direction by using publicly available social bookmarks as indicators of worth. Paradoxically, this approach is doomed to fail if it enjoys any success. If it becomes popular, it would be all to easy for tricksters to create false bookmarks for the sole purpose of inflating the ranks of chosen pages. It's the same lesson that Google is learning now with googlebombing: You can never trust random pages on the internet. Not even social bookmark pages.]